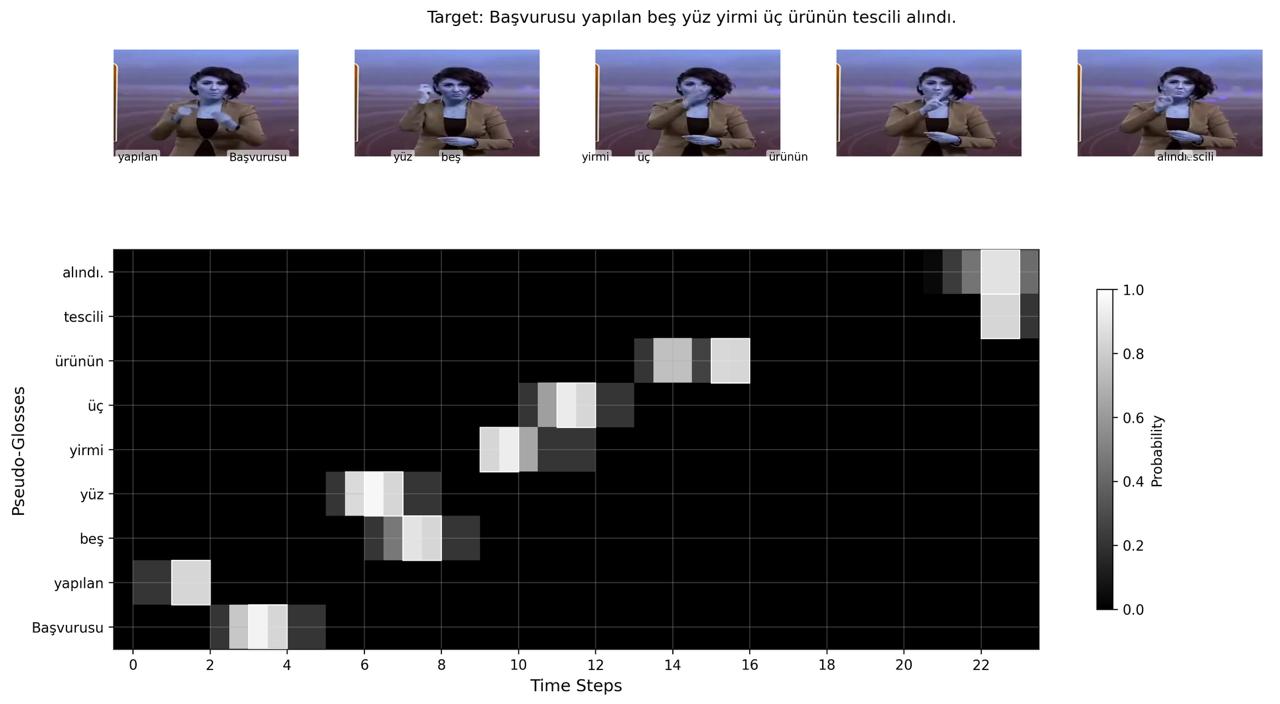
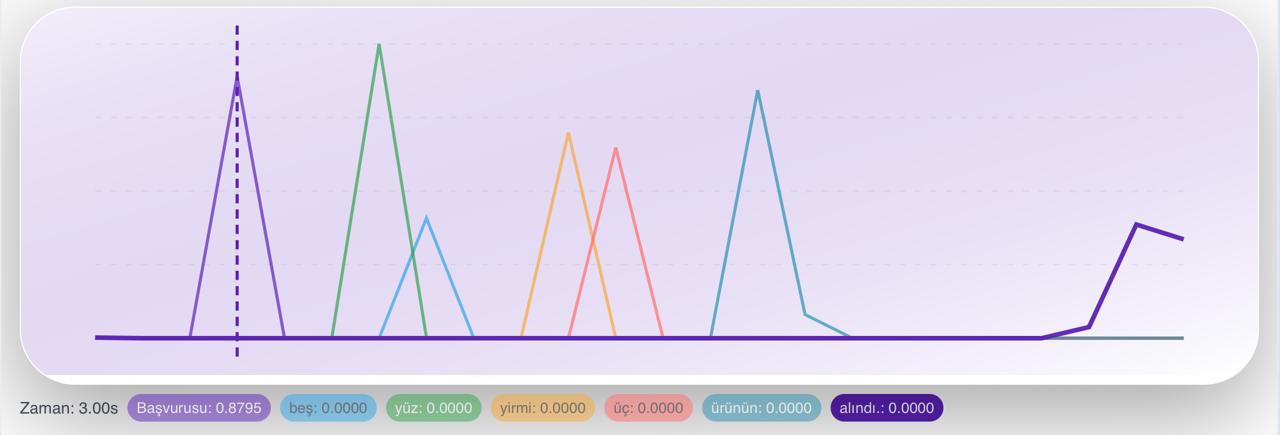
Pipeline
Visual Feature Extraction
Individual frames are encoded by a DINOv2 Vision Transformer backbone pretrained via large-scale self-supervised learning. Each frame yields a high-dimensional feature embedding that captures rich spatial and textural information about the signer's hand shape, position, and body posture.
Temporal Sign Encoding
Frame embeddings are processed by a temporal sign encoder that models how signs evolve across consecutive frames — producing temporally-aware representations that carry both spatial and motion information. This is essential since sign meaning is defined by movement trajectories, not individual still frames.
Pseudo-Gloss Supervision
Words are extracted automatically from sentence transcripts. Turkish morphological analysis lemmatizes inflected forms, collapsing ~16,000 surface entries to 4,802 lemmas. Each lemma is associated with a learnable prototype; the encoder learns to activate when the corresponding concept appears visually in the video.
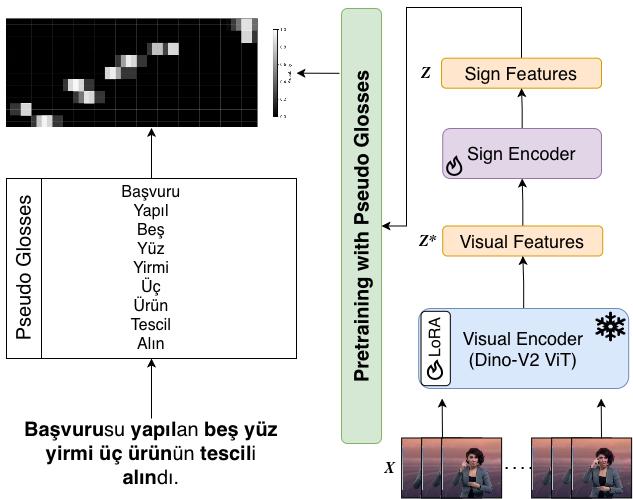
Training Strategy
The framework was trained under a weakly supervised learning setting — no frame-level sign annotations, temporal boundaries, or sign-order gloss labels were available during training. Supervision is derived exclusively from sentence-level transcripts and the automatically generated pseudo-gloss vocabulary.
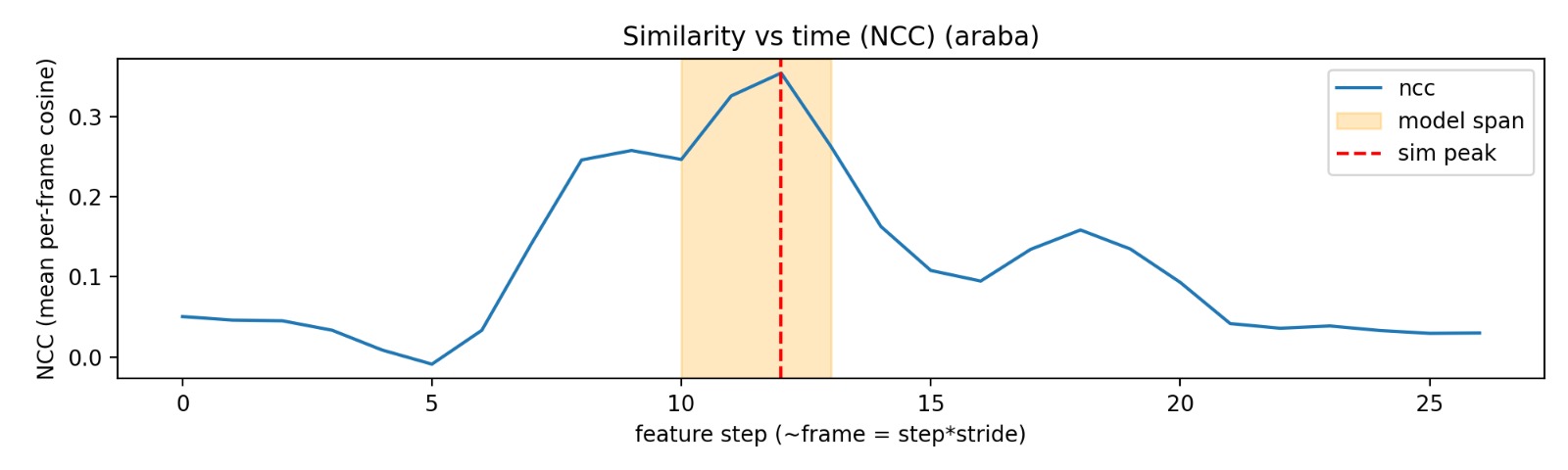
Training proceeded in two stages: pseudo-gloss training, where the model learns to detect whether a concept is present in a video sequence; and representation learning, where the temporal sign encoder aligns visual features with pseudo-gloss prototypes. Cosine similarity between projected sign features and prototype embeddings is converted to temporal probability distributions via temperature-scaled normalization. Peaks in these distributions indicate candidate sign locations — discovered without any explicit temporal supervision.